Outputs
Snapshots
The output spacing for group catalogues and snaphots has been selected as follows:
- constant in dlog(a)= 0.0081 below z=3 (171 dumps)
- constant in dlog(a)= 0.0162 between z=3 and z=10 (62 dumps)
- constant in dlog(a)= 0.0325 between z=10 and z=30 (32 dumps)
All together 265 dump times. At these dump times, the FOF and SUBFIND-HBT group finders have always been run, and the merger tree builder routine establishes on-the-fly links to previous output times. Also, matter power spectra are computed and stored. (For some runs, a few extra dumps at intermediate times were actually produced, due to a hick-up in the routine that selects the output times after a code restart - this means that for some simulations we have actually 266 or even 269 output times. This unfortunately slightly complicates the matching of equal-time output numbers between runs, but the intended 265 times are always available for all runs.)
Classical snapshot dumps with full phase-space information for all particles are however not stored for the majority of these output times, but have only been created for a reduced subset of output times. The selected redshifts for these dumps were: z = 0, 0.25, 0.5, 1.0, 1.5, 2.0, 3.0, 4.0, 5.0, and 7.0 (10 full dumps), with corresponding dump numbers 264, 237, 214, 179, 151, 129, 094, 080, 069, and 051.
Full snapshot data is stored in files with names
snapdir_XXX/snapshot_XXX.Y.hdf5
where XXX is the snapshot number, and Y enumerates the different files making up the full dump in GADGET/AREPO multi-file output format.
For all output times, the code additionally creates snapshot files named
snapdir_XXX/snapshot-prevmostboundonly_XXX.Y.hdf5
which contain only those particles that used to be a most-bound particle of a subhalo sometime in the past. These particles can be used to approximately track in semi-analytic models so-called orphaned galaxies whose dark matter substructure has been disrupted. After the merger trees have been created, the code converts the files into
snapdir_XXX/snapshot-prevmostboundonly-treeorder_XXX.Y.hdf5
which represent a reshuffling of the particle data in the order of the
trees to which each particle belongs.
'Belonging' here means that the subhalo(s) in
which a given particle was most bound are associated with
the particle, and in turn the particle is associated with the tree
these subhalos are in. (Note that the tree construction makes sure that
all subhalos a give particle belongs to are always in the same tree,
hence assignment of a particle ID to a tree ID is unique.) When the
L-Galaxies semi-analytic model processes a tree, it can retrieve
the particle data of just its tree (any nothing more) from the
snapshot-prevmostboundonly-treeorder files in order to update
the phase-space coordinates of orphaned galaxies.
Group catalogues
Group catalogues are saved in the majority of cases without explicit particle data, i.e. all available group and subhalo information must be computed on the fly.
Group data is stored in
groups_XXX/fof_subhalo_tab_XXX.Y.hdf5
files, which hold both the FOF-group and subhalo information. In case a corresponding full dump is stored, the particle data is stored in a nested fashion, biggest FOF halo first (and then in descending order), with the particles making up each subhalo within a FOF group being stored in descending order as well. Within each subhalo, the particles are ordered by increasing binding energy. It is thus possible to selectively load the particles making up each group or subhalo.
The following properties are currently stored in the group/subhalo catalogues.
For Subhalos:
| Field Name | Meaning |
|---|---|
| SubhaloPos | position (minimum of potential) |
| SubhaloVel | velocity |
| SubhaloCM | center of mass position |
| SubhaloSpin | spin vector |
| SubhaloVelDisp | velocity dispersion |
| SubhaloVmax | maximum Vc |
| SubhaloVmaxRad | radius where this is attained |
| SubhaloHalfmassRad | radius containing half the mass |
| SubhaloIDMostbound | ID of most bound particle |
| SubhaloLen | number of particles |
| SubhaloMass | total mass |
| SubhaloLenType | type-specific length (for hydro/neutrino runs) |
| SubhaloMassType | type-specific mass (for hydro/neutrino runs) |
| SubhaloHalfmassRadType | type specific half-mass radius |
| SubhaloGroupNr | FOF group number of this subhalo |
| SubhaloRankInGr | rank of subhalo in this group |
| SubhaloParentRank | for nested subhalos, gives parent subhalo in group |
| SubhaloLenPrevMostBnd | needed to retrieve previously most bound particles in this subhalo |
| SubhaloOffsetType | first particle in output snapshot in this subhalo |
For FOF groups:
| Field Name | Meaning |
|---|---|
| GroupPos | position (minimum potential) |
| GroupVel | bulk velocity |
| GroupMass | mass |
| GroupLen | particle number |
| GroupLenType | type specific length |
| GroupMassType | type specific mass |
| Group_M_Crit200 | spherical overdensity mass/radius |
| Group_M_Crit500 | (accounting for all mass around GroupPos) |
| Group_M_Mean200 | |
| Group_M_TopHat200 | |
| Group_R_Crit200 | |
| Group_R_Crit500 | |
| Group_R_Mean200 | |
| Group_R_TopHat200 | |
| GroupFirstSub | index of first subhalo in FOF group |
| GroupNsubs | number of bound subhalos in group |
| GroupOffsetType | gives index of first particle in output belong to this group |
| GroupLenPrevMostBnd | needed to retrieve previously most bound particles in this group |
Descendant and progenitor information
While the simulation code is running, two subsequent group/subhalo catalogues are linked together
by tracking the central most bound particles of each subhalo. For every group catalogue XXX, there are
files
groups_XXX/subhalo_prog_XXX.Y.hdf5
giving the progenitor subhalo(s) in the previous output XXX-1. Likewise, for every group catalogue, there are
groups_XXX/subhalo_desc_XXX.Y.hdf5
files that give access to the descendant(s) of a subhalo in the next output XXX+1. The meaning of these pointers is illustrated in the following diagram:
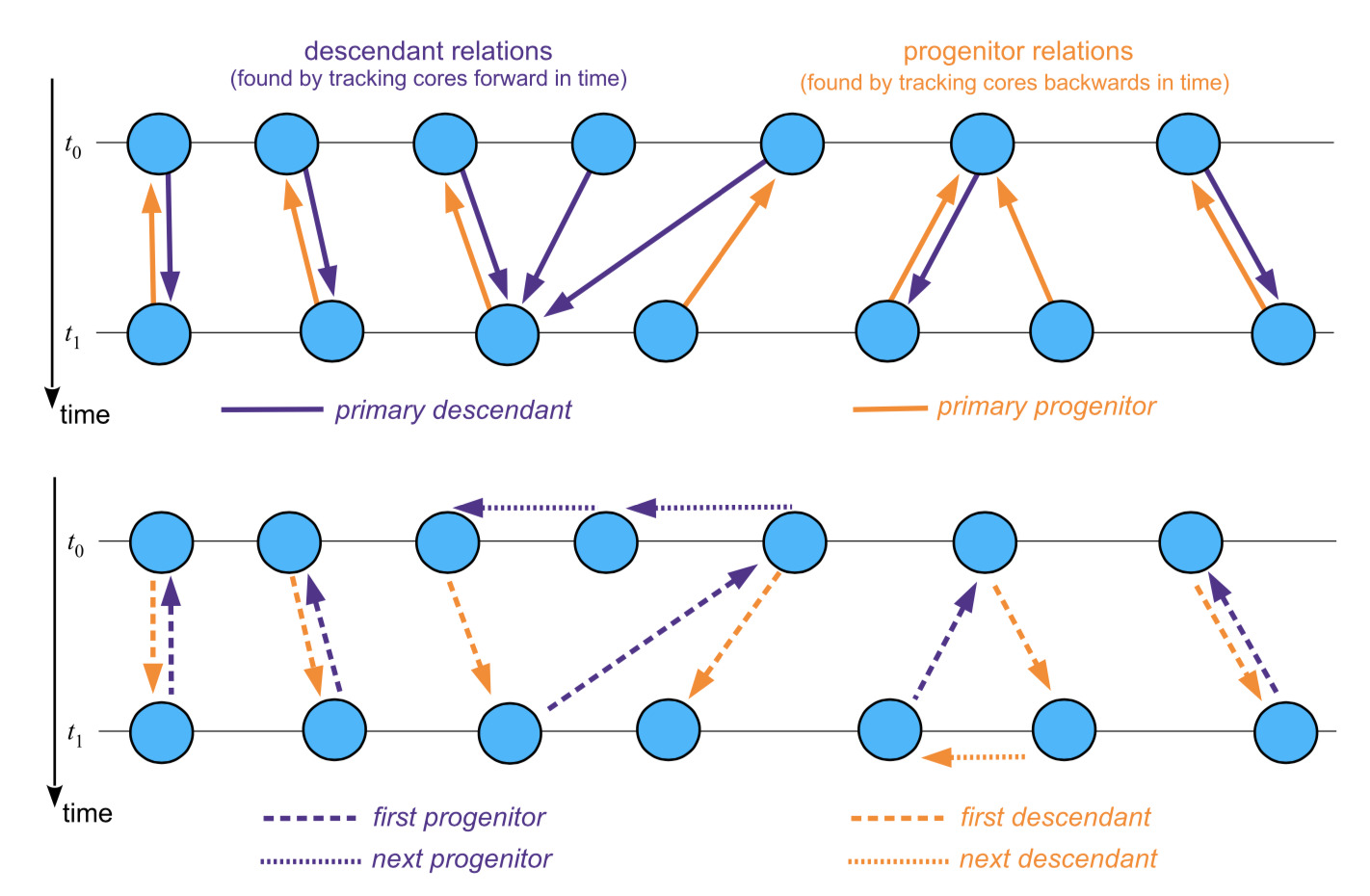
At the end of a simulation run, the code is restarted in a special mode to combine all this linking information into more easily accessible merger trees, but in principle these files can also be accessed, if desired, to hop from one instant forward or backwards in time.
Mergertrees
The merger tree data combines all the group/subhalo catalogue information into a set of merger trees that can be read individually. Conceptually, the tree is organized as sketched below (described in detail in the GADGET-4 code paper):
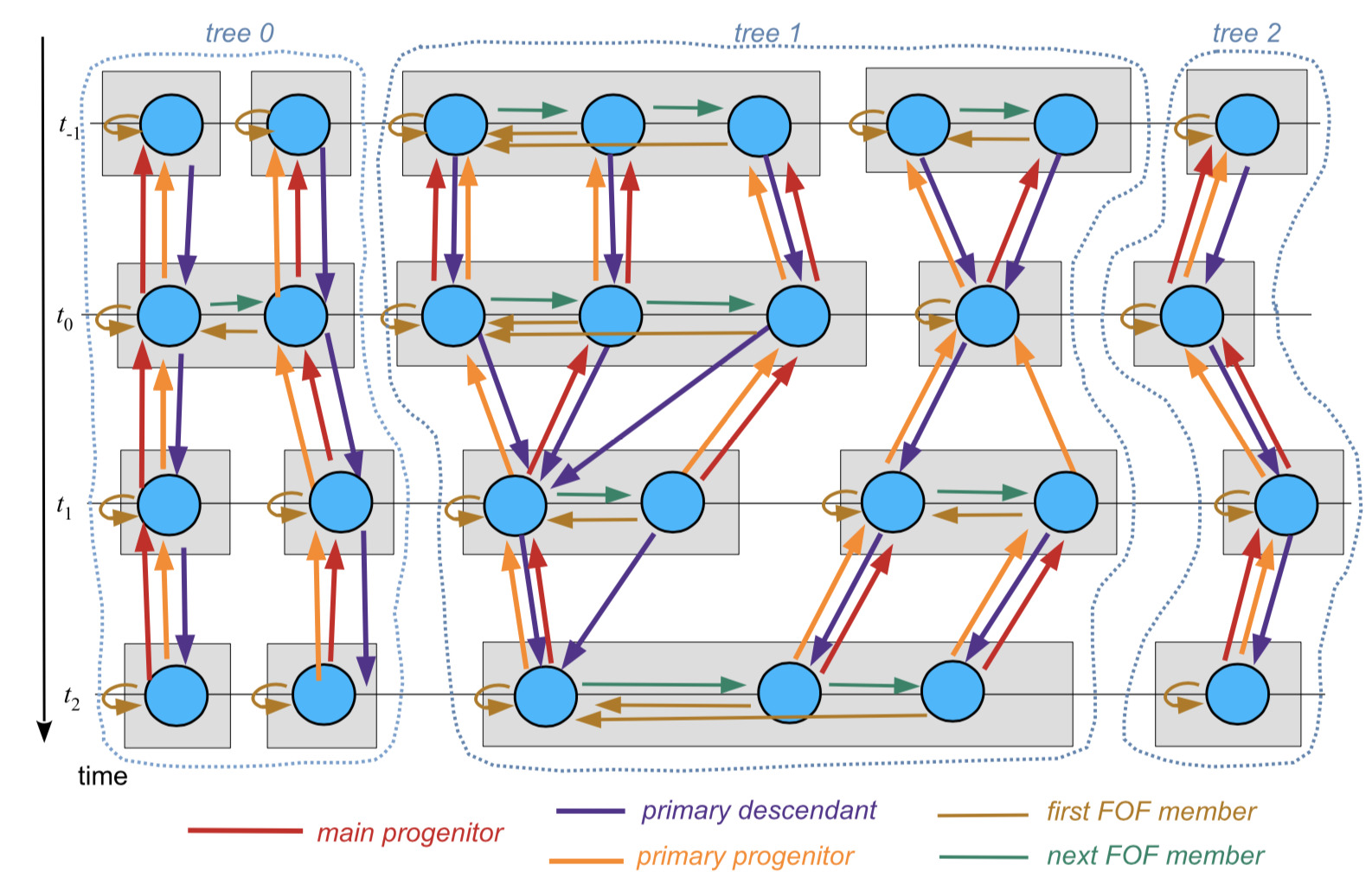
The trees are stored in files with name
treedata/trees.Y.hdf5
where Y enumerates the files making up the full catalogue when split over several files in the multi-file format.
When the trees are made, the code also creates further auxiliary files named
groups_XXX/subhalo_treelink_XXX.Y.hdf5
These tell for each subhalo in which tree and at which place within the tree the corresponding subhalo can be found. One can then selectively load this tree if desired and examine the history and fate of the subhalo.
Lightcone output
A set of different lightcones is produced by each run (periodic box replication is automatically applied to the extent necessary to fill the geometry of the specified cone):
| Cone Number | Lightcone Type | Redshift Range | Outer Comoving Distance |
|---|---|---|---|
| Cone 0 | full sky particle lightcone | z = 0 - 0.4 | ~1090 Mpc/h |
| Cone 1 | one octant particle lightcone | z = 0 - 1.5 | ~3050 Mpc/h |
| Cone 2 | pencil beam particle lightcone, square footprint (10 degree)^2 | z = 0 - 5.0 | ~5390 Mpc/h |
| Cone 3 | disk-like particle lightcone, 15.0 Mpc/h thickness | z = 0 - 2.0 | ~3600 Mpc/h |
| Cone 4 | full sky, only most-bound particles (for SAMs) | z = 0 - 5.0 | ~5390 Mpc/h |
Each lightcone is stored in its separate directory, and the individual lightcones are broken up into onion-like shells with a numbering increasing from high redshift to low redshift. This is because the code buffers lightcone data internally, and outputs a new shell whenever the buffer is full. The redshift boundaries of these onion shells have no particular meaning, and vary for different simulations. The lightcone data is stored in files
lightcone_NN/conedir_XXXX/conesnap_XXXX.Y.hdf5
where NN denotes the cone number, XXXX is the shell number, and
Y the filenumber within the mult-file output for the current
shell. The actual particle data of the lightcone output are stored in
a format closely analogous to snapshot files, but within each onion-like
shell, the particles are stored in healpix order (in principle, the code could
also find groups and subhalos directly among the lightcone particles,
but we have not enabled this feature because it is not necessary for the semi-analytics). Combined with an offset table to the first particle in each healpix pixel, this allows
selective reads of certain regions of the sky, if desired. Besides
positions and velocities, the total peculiar gravitational accleration
is also stored for particles crossing the lightcone.
For cone #4, the lightcone data is available in a secondary reshuffled order, with filenames of the form
lightcone_treeorder_04/conedir_XXXX/conesnap_XXXX.Y.hdf
Here, the particle data within each shell (which consists only of
previously most bound particles in subhalos) is reshuffled such that
they are stored in sequence of the trees to which the particles belong
(see also the discussion for the
snapshot-prevmostboundonly-treeorder files). Similar to
snapshot-prevmostboundonly-treeorder, this serves to allow the
semi-analytic code update in an exact fashion the phase-space coordinates of
subhalos and orphan galaxies when they cross the lightcone.
Mass-shell outputs
For weak-lensing applications, we create onion-like shells of the full particle light cone onto a healpix tesselation of the sky. The comoving depth of these shells is 25 Mpc/h, and they go out to redshift z=5, giving 216 such maps in total.
The number of pixels in each maps is
Npix = 12 * Nside^2
and in the highest resolution maps we go up to Nside = 12288, yielding 1.8 billion pixels and
a 0.28 arcmin angular resolution of the mass maps. The filenames of
these mass projections are
mapsdir_XXX/mapsdir_XXX.Y.hdf5
where XXX is the shell number, and Y is the number of the subfile
in multi-file decomposition of the full healpix map. angular resolution
Power spectra
As mentioned above, matter power spectra are measured for all defined
dump times (both for the total matter, and where available separately
for baryons and dark matter). Three power spectra measurements are
done each time, applying the folding technique twice with folding factors of
16 and 16^2. Combination of the measurements allows coverage of
the full spatial dynamic range of the simulations, for k-ranges that reach well below the softening
scale.
The power spectra are stored in the files named
powerspecs/powerspec_XXX.txt
and for the hydrodynamical runs in addition in
powerspecs/powerspec_type0_XXX.txt
powerspecs/powerspec_type1_XXX.txt
powerspecs/powerspec_type4_XXX.txt
powerspecs/powerspec_type5_XXX.txt
for gas, dark matter, stars and black holes separately.
Flatfiles
While the merger trees in the HDF5 files treedata/trees.Y.hdf5, and
the most-bound particle data in
snapdir_XXX\snapshot-prevmostboundonly-treeorder_XXX.Y.hdf5, allow
the semi-analytic code L-Galaxies to access all input data for
processing of a tree in a convenient way (and in particular without
the need to read any extra data from other trees), the I/O is nevertheless slowed down
tremendously by the overhead of having to open a large number of files to collect the data
(due to the distribution of the data across a larger number of output
times, and across multiple files each time), and then fast forwarding in the
files to a number of different positions. The HDF5 library, in particular, adds
significant additional overhead to this, which is further amplified
by our decision to store some of the fields with lossless
on-the-fly compression (transparently applied by HDF5) to save disk space. This overhead is so large that running the semi-analytic code is completely dominated by it. We are talking of a slowdown by more than a factor of 100 here.
In order to circumvent this issue, the HDF5 input files for L-Galaxies have additionally been recast into a binary flat file structure, where all the data needed for one tree is stored in a contiguous block and can thus be read with a single read-statement. This eliminates the HDF5 overhead and only one file opening operation is needed at start-up of the code. These flat files are called
PartData
PartCount
PartOffset
TreeData
TreeCount
TreeTimes
and can be viewed as (pretty large) scratch files that do not need to be archived long-term, but can always be recomputed as needed to make L-Galaxies run faster.